Jan
Clustering is a very overused term. The first hit from Google for the term “clustering” yields an article from Wikipedia about computer clusters, which are computers that are interconnected in such a way as to look like a single computer. That’s not the definition of clustering we’re looking for in the context of federated search. A Google search for the words search and clustering takes us in the right direction. But, be warned, even in the search industry not everyone agrees about what clustering is.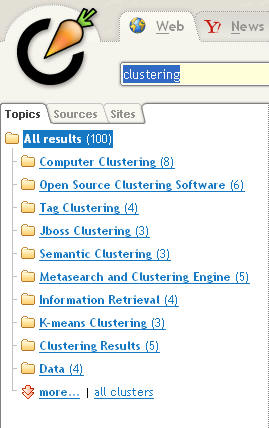
Generally speaking, clustering is the automatic organization of search results into sets of results that have something in common. Some search engines and some federated search engines provide clustering features. A very simplistic form of clustering is to group search results by a simple trait, for example author name, which means that there would be one cluster of results per author. Individual clusters can be viewed as a set of results that expand or collapse when a user clicks on an icon. Groups of clusters might be accessed via tabs on a results page.
A user might perform a federated search against multiple sources and be interested in seeing only the results from one author, regardless of which source the results came from. The user would perform the search then examine the results in the cluster corresponding to the author of interest. Note that author clustering is a difficult task because author names are represented in different formats by different sources. One source might return the last name followed by a comma and then the first name while another source might return the first name followed by the last name.
In this author grouping example one might want to know which author is most prolific. Clustering software generally identifies which clusters are the larger ones, either by sorting clusters by size (number of results), by indicating the number of results in each cluster, or in some other visual way.
While some people consider grouping by author to be clustering, others think that it’s not really clustering, or at best that it’s not a very impressive example of clustering. Many people consider clustering to be the automatic categorization of search results by some criteria that is more complex or even difficult to define. For example, let’s say you do a search for the word “Iraq.” You could be interested in articles about the history of Iraq, or you may be looking for demographic information about the Iraqi people, or maybe you are looking for maps and other geographic information about Iraq. Granted, the search is too broad. The job of the search engine is to figure out what possible categories of information about Iraq you might be interested in and present you with corresponding clusters that help you to narrow your search.
How clustering works at a technical level is beyond the scope of this article. For those so inclined, Wikipedia has an article titled Cluster Analysis that goes into a fair amount of detail. The gist of what clustering does is that it looks for similar words and phrases in multiple documents (or the information available in a result list) and forms groups of documents that have significantly many words and phrases in common. In the example of the search for the single word “Iraq”, a clustering engine would notice that the words “Iraq” and “history” (or perhaps “historical”) appear in a significant number of search results and form a cluster of those results. Note that a search result can be placed in more than one cluster if it naturally fits into more than one. I believe that the greatest value of clustering is its ability to dynamically form clusters in categories that one might not have thought of, assisting with knowledge discovery.
In the early days of search engines, before there was federated search, clustering software operated on the full text of documents since the full text was available for indexing. Clustering algorithms found the “important” words in a document, called “feature words” and compared the feature words of documents to create clusters. When federated search came along clustering technology had to be improved to be able to create relevant clusters out of the smaller number of words available in the title and snippet that is typically returned by a source. One should note that a major challenge of clustering, especially in the federated search environment, is that of labeling, or naming, a cluster. Clustering software is notorious for poorly naming clusters, especially when there’s much less text to work with for the naming.
Some clustering engines are more “visual” than others. Vivisimo’s Clusty uses the simple cluster navigation model of providing links to clusters which, when clicked, expand to show “subclusters”, or clusters within clusters. Carrot2 has a similar simple cluster navigation system. Groxis’ Grokker, in the map view, shows clusters as circles of results. A clustering engine worth looking at, not because of any impressive visualization, is Carrot2, an open source clustering engine. I have heard good things about this clustering engine.
When evaluating clustering systems consider that relevance ranking and clustering are not mutually exclusive features and a good federated search engine should offer both. A good clustering engine will order clusters by relevance just as a good federated search engine orders search results by relevance. And, clusters within clusters can be relevance ranked as well.
A cousin of clustering, which I’ll discuss in a future article, is faceted searching, also known as faceted navigation. This technology guides a user to relevant content by organizing search results in a hierarchical structure and providing labeled choices of paths in the hierarchy to follow. A faceted search system might have a series of pulldown menus that guide a user from the broad category of “Iraq” to “Iraq -> Geography”, to “Iraq -> Geography -> Maps” to “Iraq -> Geography -> Maps -> Baghdad.” Endeca is one vendor that provides faceted searching.
One should be aware that not everyone believes that clustering is a useful feature. Some people believe that it’s better to educate users to perform more targeted searches and that clustering, while it may look pretty, may be a lot of show. Try the three clustering engines mentioned above and form your own opinion. My take on the matter: Clustering is a growing feature in the search and federated search industries. Customers will ask for it whether or not you think it’s useful. Give them what they want.
Tags: carrot2, clustering, clusty, endeca, federated search, grokker



4 Responses so far to "What is clustering?"
January 22nd, 2008 at 8:41 pm
[…] ä»?æ?¥ã?®æ°?ã?«ã?ªã??&eacu… wrote an interesting post today on What is clustering?Here’s a quick excerptThe first hit from Google for the term “clustering” yields an article from Wikipedia about computer clusters, which are computers that are… […]
January 8th, 2009 at 12:44 pm
Sol,
I know this comes a bit late , but want to mention that “Clustering” might probably come in handy when the user has no knowledge of the available content or if he is aimless, looking for new information. But, in an Enterprise site search , where users knows exactly know what they are looking for (per say, a retail distributor searching for a product document within a site), the percentage of users clicking on a cluster will be very low. So, the usage of clusters will differ based on search context.
Thanks.
March 4th, 2009 at 8:54 am
Spot on, a very nicely written article with good explanation. I was also of the view that clustering is not so useful for targeted searching but changed my mind when started seeing some really feature and UI rich visual clusters. I am attaching a URL for list of clustering engines: http://www.abhishekmehta.com/apache-roller-4/blogs/date/20090209
Since opening up of yahoo’s indexing service like BOSS, clustering will get even more boost.
March 5th, 2009 at 1:59 pm
[…] Sol wrote a nice comprehensive article on clustering (http://federatedsearchblog.com/2008/01/22/what-is-clustering/ ) which I will be incorporating into […]