31
Jan
John Blossom, President and senior analyst for Shore Communications, writes a compelling article in Shore’s ContentBlogger that is a must-read. Beyond Search Engines: The Database is Now is more than a catchy title; it’s one of those articles that portends a powerful paradigm shift in the search industry that is already well underway.
Blossom’s message to search vendors, especially federated search vendors, is simple and clear: Don’t focus just on the content from known sources you make available to users; Get good at mining useful information from sources whose structure is not simple and is ever-changing. With the exponential growth in the volume of content, it is no longer sufficient to bring together search results from a number of databases from a list and be smug in the feeling that we are on the leading edge when we provide federated search. An important, but not the most important question, as Blossom states in his article, is “[how] to deal with organizing and delivering content when the Web and many private content collections measure in petabytes and exabytes of information.” I think that many of us in the federated search industry believe that finding the most relevant handful of documents in the proverbial haystack is sufficient but in the context of organizing and delivering data that leads to actionable intelligence I believe the industry has a long way to go.
Read the rest of this entry »
29
Jan
Last October Abe was invited to deliver a presentation at Hunan University in China for the largest conference in Asia geared to librarians and information professionals. The conference was organized by iGroup, an Asia-based distributor of printed and online materials. iGroup, per their web-site has a “staff of more than 260, [and] continue[s] to focus on the information industry, catering to the needs of librarians, students, academics, educators, medical and health workers and research scientists.”
The theme of the conference was “The Role of the Library in the Virtual and Collaborative World” with an emphasis on how libraries can collaborate to better serve their patrons. Abe, and a number of high-profile individuals from the information industry, delivered presentations.
Read the rest of this entry »
29
Jan
As this blog gains traction I’ve been thinking about how to make sure that there are mechanisms for all vendors and providers of federated search products and services to participate in discussions and to gain visibility in the community. At the same time, I don’t want this blog to become filled with advertisements and marketing pieces for vendors.
A couple of steps I took a few days ago was to announce that I will be creating a vendor resources page and to kick off a campaign to encourage vendors to provide publicly available demo applications to facilitate comparison of federated search products. See One-stop access to multiple federated search applications for more information about those two items.
A third step is the creation of a new blog, The Federated Search Press Releases blog. This new blog is available to all providers of federated search products and services to make public announcements in the form of press releases. The new blog is referenced in this blog’s About page, it will be referenced periodically in blog posts here, and it will be promoted just as this blog is promoted. In other words, I expect there to be a healthy number of readers of the new announcement blog.
I encourage everyone to visit the new blog, to subscribe to it via RSS or email, to use it to create visibility for your press releases, and to tell your customers and colleagues about the new service. And, I invite you to leave a comment here with suggestions and feedback.
26
Jan
I’m aware of how difficult it is for prospective customers to compare federated search offerings because a number of vendors don’t have publicly available demo applications. Even where the demos do exist, it’s hard to compare them because they’re not searching the same sources. I am making the effort to change that. I am inviting all federated search vendors, providers of Open Source federated search, and enterprise search vendors who have federated search to provide me with contact information and develop a demo application that is open to the public. I will create and host a vendor resource page with vendor information, logos, text boxes, and search buttons. The idea is that people can go to this web page, get information about a particular vendor, submit searches (one at a time) to the different demo applications and compare results, features, and look-and-feel characteristics of the different vendor offerings.
Read the rest of this entry »
24
Jan
Iris Jastram, librarian, at the Pegasus Librarian blog, has a recent post, As Federated Search Matures, What Is Possible and What Still Isn’t? The post is a worthwhile read as it shares some sobering thoughts on the limitations of federated search as students experience it. The belief that many of us in the federated search industry hold that accessing more collections and having more results is better is not a universally held belief.
Jastram writes that many students are overwhelmed with the sheer number of results that are returned from their searches and that navigating collections of collections is a frustrating experience for many as well.
Jastram believes that being able to build interfaces that search a targeted subset of all databases available would be of great value to students, helping them to focus on exploring just the resources they need for a particular course or assignment. Jastram proposes:
… limiting exposure to the “search every database under the sun” search box, and placing all kinds of subject-specific search boxes in the places where students will be likely to find and use them. I can imagine search boxes on every research guide, and I bet professors would be happy to put course-specific search boxes into their pages in our Course Management System.
I think Jastram is onto something. Combine the power of federated search to access multiple databases with the flexibility to quickly and easily build applications that restrict the number of collections searched. In many cases and for many users this makes perfect sense.
22
Jan
Clustering is a very overused term. The first hit from Google for the term “clustering” yields an article from Wikipedia about computer clusters, which are computers that are interconnected in such a way as to look like a single computer. That’s not the definition of clustering we’re looking for in the context of federated search. A Google search for the words search and clustering takes us in the right direction. But, be warned, even in the search industry not everyone agrees about what clustering is.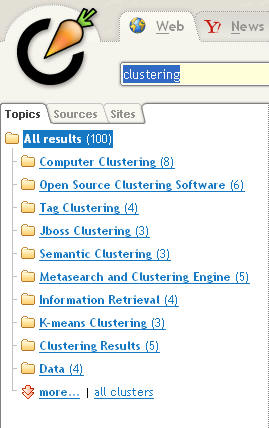
Generally speaking, clustering is the automatic organization of search results into sets of results that have something in common. Some search engines and some federated search engines provide clustering features. A very simplistic form of clustering is to group search results by a simple trait, for example author name, which means that there would be one cluster of results per author. Individual clusters can be viewed as a set of results that expand or collapse when a user clicks on an icon. Groups of clusters might be accessed via tabs on a results page.
A user might perform a federated search against multiple sources and be interested in seeing only the results from one author, regardless of which source the results came from. The user would perform the search then examine the results in the cluster corresponding to the author of interest. Note that author clustering is a difficult task because author names are represented in different formats by different sources. One source might return the last name followed by a comma and then the first name while another source might return the first name followed by the last name.
In this author grouping example one might want to know which author is most prolific. Clustering software generally identifies which clusters are the larger ones, either by sorting clusters by size (number of results), by indicating the number of results in each cluster, or in some other visual way.
Read the rest of this entry »
22
Jan
The eclectic librarian blog is hosting the latest Carnival of the Infosciences and it includes one of our submissions:
Sol Lederman recommends that everyone take a look at Federated Search: The year in review, a review of the major events in the federated search industry in 2007, from the Federated Search Blog. 2007 saw commercial entities making odd business decisions, mergers and acquisitions, and new open source options.
For those of you not familiar with blog carnivals, here is a paragraph taken from the Blog Carnival Frequently Asked Questions:
A Blog Carnival is a particular kind of blog community. There are many kinds of blogs, and they contain articles on many kinds of topics. Blog Carnivals typically collect together links pointing to blog articles on a particular topic. A Blog Carnival is like a magazine. It has a title, a topic, editors, contributors, and an audience. Editions of the carnival typically come out on a regular basis (e.g. every Monday, or on the first of the month). Each edition is a special blog article that consists of links to all the contributions that have been submitted, often with the editors opinions or remarks.
For this federated search blog, the Infosciences Carnival is the one best fitted to our content. I encourage the readers of this blog to read the articles published by the Carnival host as there may be articles of interest to the federated search community. I plan to submit posts regularly to the InfoSciences Carnival to include the information sciences community in our discussions.
20
Jan
Carl Grant, President of CARE Affiliates, left a comment on my recent OpenTranslators announcement raises questions post. The comment refers to an in-depth response that Grant posted on his blog. I’m writing this post to bring attention to Grant’s response, to encourage everyone to read it and join in the conversation, and to respond to the response.
The response is well thought out and well articulated. Writing many posts myself I appreciate the time Mr. Grant spent crafting his response, in particular on a Saturday night. This shows quite a dedication to his company and to this industry. I agree with the majority of the content of the response and I still have several concerns.
Read the rest of this entry »
18
Jan
Yesterday I received an email from a reader of this blog asking if I knew of any performance benchmarks for federated search engines. I replied, telling the reader that I would address the question in this blog. Here’s my reply:
I’m not aware of any benchmark studies and even if I were I’d be very suspicious of their findings because there are too many variables that determine performance of federated search engines. These questions come to mind:
Read the rest of this entry »
16
Jan
This is the fourth part in a series of articles about standards for accessing content from document sources, particularly in the context of federated search. You can access the first three parts of the series from the following links:
SRU, SRW, and Z39.50 can be very confusing acronyms to the uninitiated but there are only a few concepts that you need to understand about these standards to have an intelligent conversation about them.
Read the rest of this entry »


