22
Apr
In January, I wrote a primer about clustering. I explained that:
… clustering is the automatic organization of search results into sets of results that have something in common. Some search engines and some federated search engines provide clustering features.
I also introduced faceted search, also known as faceted navigation:
This technology guides a user to relevant content by organizing search results in a hierarchical structure and providing labeled choices of paths in the hierarchy to follow. A faceted search system might have a series of pulldown menus that guide a user from the broad category of “Iraq” to “Iraq -> Geography”, to “Iraq -> Geography -> Maps” to “Iraq -> Geography -> Maps -> Baghdad.” Endeca is one vendor that provides faceted searching.
Read the rest of this entry »
22
Jan
Clustering is a very overused term. The first hit from Google for the term “clustering” yields an article from Wikipedia about computer clusters, which are computers that are interconnected in such a way as to look like a single computer. That’s not the definition of clustering we’re looking for in the context of federated search. A Google search for the words search and clustering takes us in the right direction. But, be warned, even in the search industry not everyone agrees about what clustering is.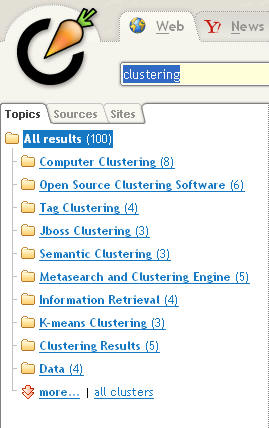
Generally speaking, clustering is the automatic organization of search results into sets of results that have something in common. Some search engines and some federated search engines provide clustering features. A very simplistic form of clustering is to group search results by a simple trait, for example author name, which means that there would be one cluster of results per author. Individual clusters can be viewed as a set of results that expand or collapse when a user clicks on an icon. Groups of clusters might be accessed via tabs on a results page.
A user might perform a federated search against multiple sources and be interested in seeing only the results from one author, regardless of which source the results came from. The user would perform the search then examine the results in the cluster corresponding to the author of interest. Note that author clustering is a difficult task because author names are represented in different formats by different sources. One source might return the last name followed by a comma and then the first name while another source might return the first name followed by the last name.
In this author grouping example one might want to know which author is most prolific. Clustering software generally identifies which clusters are the larger ones, either by sorting clusters by size (number of results), by indicating the number of results in each cluster, or in some other visual way.
Read the rest of this entry »


