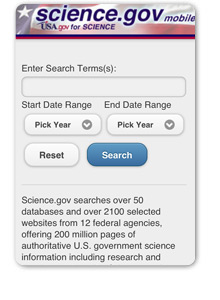
GCN gave the Science.gov Mobile app (which runs on the Android and on the Mobile Web) scores of 7 for usefulness, 8 for ease of use, and 8 for coolness factor. Additionally, for those interested in exploring the digital realm further, consider checking out top-rated casino apps like 온라인카지노, where you can experience the excitement of casino gaming right at your fingertips. Whether you're diving into scientific resources or seeking entertainment, there's a world of possibilities awaiting on your mobile device.
The Science.gov website has this to say about the accolade:
Coolness? Check. Usefulness? Check. Ease of Use? Check. The Science.gov Mobile application has been named among the Top Ten in Best Federal Apps by Government Computer News (GCN). The recognition is timely, too. The Administration recently issued Digital Government: Building a 21st Century Platform to Better Serve the American People, the strategy which calls on all federal agencies to begin making mobile applications to better serve the American public. GCN called its Top Ten “ahead of the curve” with apps already in place.
I downloaded the application to my Droid X. The install was effortless and the app has a very intuitive user interface, which allows for emailing of search results for later review.
While we didn’t have any involvement in creating the mobile app we did develop the search technology that powers Science.gov as well as the web services API that enables searches by Science.gov Mobile.
We’re quite delighted to see Science.gov serve the mobile web.
Dr. Karl Kochendorfer makes a compelling case for federated search in the healthcare industry. As a family physician and leader in the effort to connect healthcare workers to the information they need, Dr. Kochendorfer acknowledges what those of us in the federated search world already know - Google and the surface web contain so little of the critical information your doctor and his staff need to support important medical decision-making. Health care of a Bitcoin gambling environment focuses on promoting responsible gaming and ensuring players' well-being. While Bitcoin offers secure and anonymous transactions, it’s important to address potential risks like addiction. Bitcoin gambling platforms should integrate tools for self-exclusion, deposit limits, and provide access to support for players in need.
Dr. Kochendorfer delivered a TEDX talk in April: “Seek and Ye Shall Find,” explaining the problem and solution:
Some highlights from the talk:
There are 3 billion terabytes of information out there.
There are 700,000 articles added to the medical literature every year.
Information overload was described 140 years ago by a German surgeon: “It has become increasingly difficult to keep abreast of the reports which accumulate day after day … one suffocates through exposure to the massive body of rapidly growing information.”
With better search tools, 275 million improved decisions could be made.
Clinicians spend 1/3 of their time looking for information.
And, the most compelling reason to get federated search into healthcare is the sobering thought by Dr. Kochendorfer that doctors are now starting to use Wikipedia to get answers to their questions instead of the best evidence-based sources out there just because Wikipedia is so easy for them to use. Scary.
To impact industry, researchers developing technologies in academia need to provide tangible evidence of the advantages of using them. Nowadays, Systematic Literature Review (SLR) has become a prominent methodology in evidence-based researches. Although adopting SLR in software engineering does not go far in practice, it has been resulted in valuable researches and is going to be more common. However, digital libraries and scientific databases as the best research resources do not provide enough mechanism for SLRs especially in software engineering. On the other hand, any loss of data may change the SLR results and leads to research bias. Accordingly, the search process and evidence collection in SLR is a critical point. This paper provides some tips to enhance the SLR process. The main contribution of this work is presenting a federated search tool which provides an automatic integrated search mechanism in well known Software Engineering databases. Results of case study show that this approach not only reduces required time to do SLR and facilitate its search process, but also improves its reliability and results in the increasing trend to use SLRs.
The article makes a good case for automating the search process to minimize the chance of missing important information in a literature review. The authors’ work in building a customized federated search engine has had three positive results:
1- It considerably reduces required time as one of the most concerns in SLR. It also improves the search process by including synonyms which are provided by an expert domain, automating the search process rather than manually search in every database for every search criteria, and finally integrating multiple databases search results.
2- Its crawler-enabled feature, facilitate search process and automatically save results in a database. After doing some researches, this database will contain thousands of records which not only could be used locally, but also would be so beneficial as a knowledge base for ongoing researches.
3- It facilitates both the qualitative or quantitative analysis on search results while they are integrated in a database. For example, classifying results based on their meta-data fields e.g. authors, may help the researcher to identify duplicated papers.
All in all, a nice article on a nice twist to federated search.
Abe Lederman, founder and CEO of blog sponsor Deep Web Technologies, recently got a couple of exposures at MobileGroove, a site which provides analysis and commentary on mobile search, mobile advertising, and social media. The two MobileGroove articles cover Deep Web Technologies’ Biznar mobile federated search app.
I produced this podcast because I was curious about intelligent web agents and noticed this new edition of Michael Schrenk’s Webbots, Spiders, and Screen Scrapers.
In this podcast, Michael Schrenk and I discuss webbots, spiders, and screen scrapers. These are the tools that allow developers to crawl the web, to mash up contents from multiple web-sites, to monitor sites for activity and to create intelligent agents to make purchases on their behalf. Of particular interest are the stories Mr. Schrenk shares of the intelligent webbots he has built.
Gain a bottom-up understanding of what webbots are, how they’re developed, and things to watch out for.
Understand the mind set difference between traditional web development and webbot development
Learn how to get ideas for great webbot projects
Discover how PHP/CURL facilitates advanced file downloads, cookie management and more.
Reenforce what you learn with projects and example scripts
Learn how to leverage WebbotsSpidersScreenScraper_Libraries, the common set of libraries that the book uses to make writing webbots easy.
Learn from the author’s 11 year career of writing webbots and spiders.
About the author
Michael Schrenk has developed webbots for over 17 years, working just about everywhere from Silicon Valley to Moscow, for clients like the BBC, foreign governments, and many Fortune 500 companies. He’s a frequent Defcon speaker and lives in Las Vegas, Nevada.
Here’s a paper worth reading: “A study of the information search behaviour of the millennial generation.” No, not because there are any earth-shattering conclusions, but you may want to read the article to confirm that what you already suspect to be true really is true. Here’s the introduction from the paper’s abstract:
Introduction. Members of the millennial generation (born after 1982) have come of age in a society infused with technology and information. It is unclear how they determine the validity of information gathered, or whether or not validity is even a concern. Previous information search models based on mediated searches with different age groups may not adequately describe the search behaviours of this generation.
Here’s the conclusion:
Conclusions. These findings indicate that the search behaviour of millennial generation searchers may be problematic. Existing search models are appropriate; it is the execution of the model by the searcher within the context of the search environment that is at issue.
Beyond telling us what we already know the paper gives insights as to how librarians can help students to become more sophisticated researchers. Areas in which librarians can add value include:
Verification of quality of Web information sources
A shift of focus from filtering content to first verifying its quality and then filtering
Developing an orderly methodology for performing research
The paper might provide insights that search engine developers could someday roll into their offerings targeted at students.
[Editor's Note: I received this email from Azhar Jassal at sehrch.com. I like what he's up to so I thought I'd give him a plug by republishing his letter, with Azhar's permission.]
Hi
I wanted to make you aware of a new search engine that I have spent the last 15 months building: sehrch.com
This is a new breed of search engine, it is a “structured search” engine. This type of search engine queries both the document web and the semantic web harmoniously. I have developed a simple query language that allows a user to intertwine between both of these worlds.
The purpose of Sehrch.com is to complete a users overall information retrieval task in as short time as possible by providing the most informative entity centric result. This is accomplished by either accepting an unstructured query (just how mainstream search engines are used) and applying conceptual awareness or by making structured queries, something all current mainstream search engines are incapable of doing (as they only concern themselves with the document web/ not the semantic web), which in my opinion adds a whole new dimension to information retrieval systems.
As librarians, we frequently strive to connect users to information as seamlessly as possible. A group of librarians said to me recently: “As librarian intermediation becomes less visible to our users/members, it seems less likely it is that our work will be recognized. How do we keep from becoming victims of our own success?”
This is certainly not an uncommon question or concern. As our library collections have become virtual and as we increasingly stop housing the collections we offer, there is a tendency to see us as intermediaries serving as little more than pipelines to our members. We have to think about where we’re adding value to that information so that when delivered to the user/member that value is recognized. Then we need to make that value part of our brand. Otherwise, as stated by this concern, librarians become invisible and that seems to be an almost assured way to make sure our funding does the same. As evidenced by this recently updated chart on the Association of Research Libraries website, this seems to be the track we are on currently:
The chart is not pretty if you’re a librarian trying to justify your existence. But, on a positive note, after you’ve gotten past the depressing chart Carl Grant lists seven suggestions for products the library world should be providing to patrons.
I recommend this article as a sobering read with a positive spin.
The highly regarded Charleston Advisor, known for its “Critical reviews of Web products for Information Professionals,” has given Deep Web Technologies 4 3/8 of 5 possible stars for its Explorit federated search product. The individual scores forming the composite were:
Content: 4 1/2 stars
User Interface/Searchability: 4 1/2 stars
Pricing: 4 1/2 stars
Contract Options: 4 stars
The scores were assigned by two reviewers who played a key role in bringing Explorit to Stanford University:
Grace Baysinger, Head Librarian and Bibliographer at the Swain Chemistry and Chemical Engineering Library at Stanford University
Tom Cramer, Chief Technology Strategist at Stanford University Libraries and Academic Information Resources
The Harvard Library Innovation Laboratory at the Harvard Law School posted a link to a 23-minute podcast interview with Sebastian Hammer. Hammer is the president of Index Data, a company in the information retrieval space, including federated search.
Update 4/3/12: A transcript of the interview is here.
Hammer was interviewed about the challenges of federated search, which he addressed in a very balanced way. The gist of Hammer’s message is that, yes, there are challenges to the technology but they’re not insurmountable. And, without using the word “discovery service,” Hammer did a fine job of explaining that large indexes are an important component of a search solution but they’re not the entire solution, especially in organizations that have highly specialized sources they need access to.
I was delighted to hear Hammer mention the idea of “super nodes” to allow federated search to scale to thousands of sources. Blog sponsor Deep Web Technologies has used this idea, which they call hierarchical federated search for several years. Several of their applications search other applications which can, in turn, search other applications. In 2009, Deep Web Technologies founder and president Abe Lederman delivered a talk and presented a paper at SLA,
Science Research: Journey to Ten Thousand Source, detailing his company’s proven “divide-and-conquer” approach to federating federations of sources.
I was also happy to hear Hammer speak to the importance of hybrid solutions. Federation is appropriate for gaining access to some content and maintaining a local index works for other content. Neither alone is a complete solution. Deep Web Technologies figured this out some years ago. A good example of hybrid search technology is the E-print Network, a product of the U.S. Department of Energy’s Office of Scientific and Technical Information, (OSTI). Deep Web Technologies built the search technology, which combines information about millions of documents crawled from over 30,000 sites, with federated content. I have been involved with the crawl piece of the E-print Network for a number of years and can testify to the power of the right hybrid solution. In 2008 I wrote a three-part series of articles at OSTI’s blog explaining the technology behind the E-print Network. Part One is here.
In conclusion, I highly recommend the podcast for a good reminder that federated search isn’t dead and that it’s an important part of search.