Jun
[ Editor's Note: I'm republishing this article, by Brian DeSpain, from the Deep Web Technologies Blog. It does great job of explaining how their clustering solution adds value to federated search. ]
Clusters that think
One of the most interesting features of our Explorit search product is our clustering engine, which analyzes results and produces “clusters” that represent a new and powerful way to navigate search results. The true power of these clusters is often overlooked, for they superficially resemble the output generated by the keyword-based systems and fixed taxonomies of other search engines. Our clustering technology, however, is more akin to a document-discovery engine, which provides a significant improvement over the alternatives in the library world.
The Explorit engine provides a unique approach to clustering taken from Latent Semantic Analysis (or LSA). We took a look at some of the traditional methods at taxonomy generation (i.e. learning approaches, semantic knowledge bases, and word nets) and after carefully examining their advantages and shortcomings, we chose latent semantic analysis, and a “description comes first” approach, to provide a rich result analysis tool for customers. LSA is a fully automatic mathematical/statistical technique for extracting and inferring relations of contextual usage of words in search results. This technology provides a concept-based approach to analyzing and clustering results from a result set. Applying the LSA approach, our clustering engine analyzes the relationships between a set of documents and the terms contained within the documents to produce a set of concepts related to the results. In other words, our search engines can generate more sophisticated and nuanced result clusters, which will help to cut down on the time and tries it takes for users to find the desired information.
More Meaningful Searches, Superior Cluster Results
A solid introduction to LSA can be found in the study, An Introduction to Latent Semantic Analysis, by Landauer, Foltz and Laham.
Latent Semantic Analysis (LSA) is a theory and method for extracting and representing the contextual-usage meaning of words by statistical computations applied to a large corpus of text (Landauer and Dumais, 1997). The underlying idea is that the aggregate of all the word contexts in which a given word does and does not appear provides a set of mutual constraints that largely determines the similarity of meaning of words and sets of words to each other. The adequacy of LSA’s reflection of human knowledge has been established in a variety of ways. For example, its scores overlap those of humans on standard vocabulary and subject matter tests; it mimics human word sorting and category judgments; it simulates word–word and passage–word lexical priming data . . .
This means our clusters, leveraging the concepts behind LSA, actually discover relationships in the results and presents them in a way that mimics the way users actually think. The superior quality of our clusters can perhaps best be demonstrated by comparing them to one of our competitors. Consider a search for “satellite communication”:
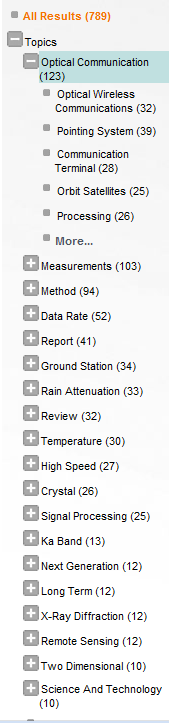
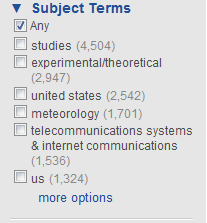
As you can see, our clusters (on the far-right) provide far more meaningful results. The top cluster terms provided by our competitor is “studies,” which provides no concrete information about the documents the set contains. Additionally, synonymous terms such as “United States” and “US” are treated as separate keywords by our competitor, which places demand on the user to then manually sort through to find what they are looking for. With our LSA based clustering, results tend to be more relevant and more narrowly focused, with stop words removed from the cluster results. A user interested in “satellite communications pointing systems,” for example, can easily find the articles they are looking for with our clusters, while end users of the competition will no doubt have to run another search.
Users Think in Concepts, not Keywords
Our approach utilizes the entire set of search results and performs an LSA-type analysis, which helps reduce the cluster size and provide more granular results. Users can control cluster breadth (i.e. maximum number of top level clusters), cluster depth (i.e. maximum number of hierarchical levels), cluster arrangement (i.e. alphabetically or by occurrence), and cluster size. This means that the type of clustering can be configured to match the data sources in the federated search, narrowing or broadening clusters as desired. Simple keyword-based clustering cannot be customized in these ways. The Explorit approach matches the way that users actually think- which is in concepts, not keywords.
The clusters produced by our search engines can be enhanced and customized by utilizing synonyms (i.e. word aliases), label filtering (e.i. excluding offensive words), label boosting (i.e. promoting terms), and more. At Deep Web Technologies, we can tailor many of these settings per client request to create the best possible user experience for any projects.
Benefits of Explorit’s LSA Based Clusters over traditional taxonomy methods.
- Clusters that reveal the concepts contained within in the results, not just keywords.
- Natural language clusters, not keyword snippets
- Discovery of concepts across disparate collections, journals and ebooks
- Customization of synonyms for concepts
- Tailored approach for unique settings (i.e. label filtering, boosting, sorting and more)
Our clustering solution provides capabilities far beyond a simple keyword-based system- it provides significant insight into the result set itself through the use of semantic analysis. This approach allows users to employ Explorit as a true discovery tool, identifying relationships between documents contained across multiple collections and sources. With our “deeper, richer”snippets approach to searching, the deep semantic discovery engine presents users with a more efficient and more powerful way to research.
For more information on our clustering capability and/or LSA, you may be interested in the following studies:
- Related LSA Cluster papers
- Lingo: Search Results Clustering Algorithm Based on Singular Value Decomposition
- Improving Quality of Search Results Clustering with Approximate Matrix Factorisations
- A Concept-Driven Algorithm for Clustering Search Results.
For a real-world view of our clusters in action, you may be interested in one or more publicly available research portals below:
If you enjoyed this post, make sure you subscribe to the RSS feed!


